MATLAB Signal Labeler vs. dFL: DSP depth, cost per seat, multi-user support, Python integration, and provenance. Side-by-side for sensor ML teams.
Read MoreThe only labeling + harmonization studio built for robotics sensor data — align multi-rate streams, label behavioral events, and autolabel at scale. Full provenance, replay anytime.
Label gait phases, contact events, servo failures, or skill boundaries manually — then scale that logic across thousands of episodes.
Align joint encoders, IMU, force-torque, and camera triggers onto one time grid — before a single label is placed.
Load Hugging Face datasets and ROS bags directly. Export to PyTorch, LeRobot, or MLflow — no bridge code required.
Handle joint states, IMU, force-torque, and contact sensors — from a 6-DOF arm to a full humanoid, at full sampling rate.
Test your labeling logic on a trimmed episode subset. Verify the output before running it across your full demonstration dataset.
Every transform, label, and model inference is logged — across sim and real data. Any teammate can reproduce the exact dataset.
Write custom Python classifiers — contact detectors, gait segmenters, sim-to-real flags — and plug them directly into dFL via SDK.
Export labeled episodes as Parquet or CSV with full provenance — ready for PyTorch, LeRobot, and imitation learning pipelines.

Your robot generates joint encoders, IMU, force-torque, and camera triggers at different rates. dFL aligns every stream onto a common time grid — enabling clean labeling, accurate episode comparison, and ML-ready datasets.

Label gait phases, contact events, skill boundaries, and failure modes directly from interactive plots. dFL lets you capture complex temporal patterns across joint states and sensor streams with precision and context.
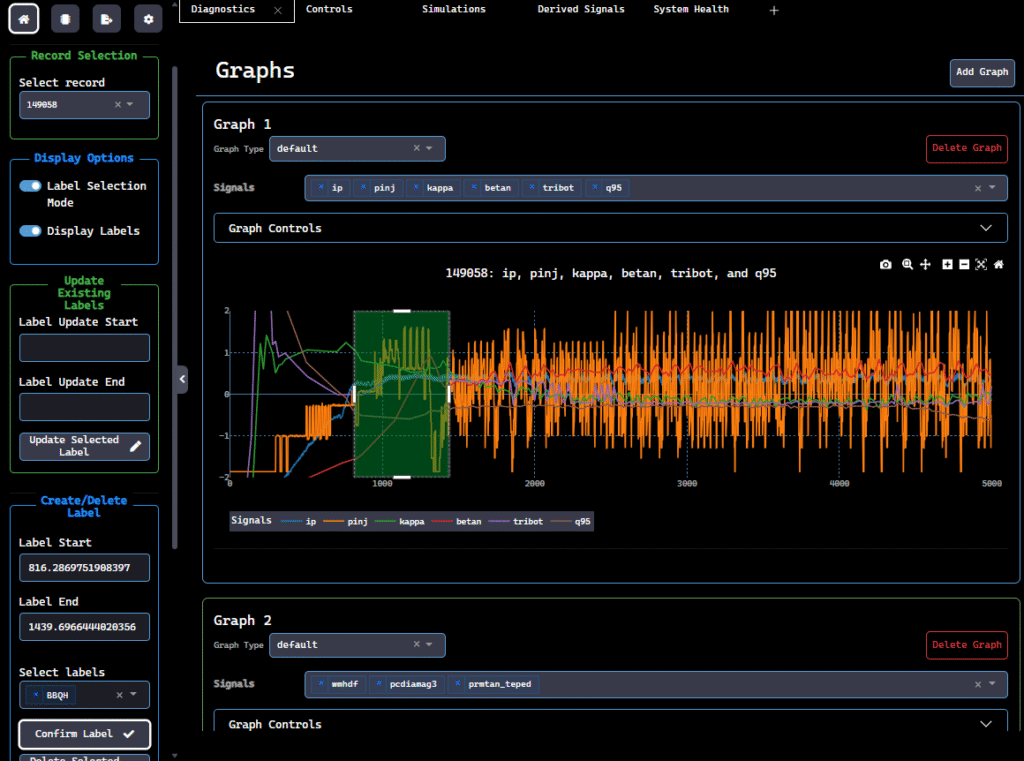

Smooth, trim, fill, or resample joint encoder and IMU streams using drag-and-drop controls. dFL’s visual DSP toolkit lets engineers preprocess robot sensor data intuitively while preserving full control over each transformation. Or, build custom pipelines that plug directly into dFL’s backend.

Use built-in anomaly detectors or plug in your own models — a servo lag classifier, a contact event detector, a gait phase segmenter. Autolabel spans across thousands of episodes, then refine with human QA. dFL’s active learning loop improves accuracy with every correction.
Export harmonized, labeled episodes in ML-ready formats. dFL preserves every step — from signal alignment to event tagging — ensuring your dataset is traceable, shareable, and ready for PyTorch, LeRobot, or any imitation learning pipeline
In this case study, we use dFL by Sophelio to open up the “black box” of robot failures in the LeRobot SO-100 sorting dataset.
Starting from raw Hugging Face logs with commanded actions and observed joint states, dFL lets robotics engineers visualize servo lag, manually mark misalignment events, and then scale that logic into a custom misalignment autolabeler.
With bulk autolabeling across episodes, teams can instantly surface problematic joints, export a curated golden dataset, and tighten their control policies without wading through hours of unstructured logs.
In this case study, we show how dFL by Sophelio helps BCI and EEG researchers answer a critical question: does preprocessing change the science?
Using pediatric EEG from the Healthy Brain Network, dFL compares two standard, defensible pipelines that differ only in whether filtering happens before or after downsampling.
The result is a side-by-side view of how alpha power, alpha reactivity, and developmental peak frequency shift under each choice—without forcing researchers to overwrite one interpretation with another.
With operation order, custom graphers, and full provenance tracking, dFL preserves meaning before modeling.
In this case study, we use dFL by Sophelio to turn a decade of raw Boston weather records into a clean, ML-ready labeled dataset.
Starting from simple multiyear signals—precipitation, temperature, and pressure—dFL handles harmonization, timestamp alignment, and exploratory visualization in a single workspace.
With a few natural language prompts, we generate an interactive threshold-based precipitation graph and a custom autolabeler that automatically flags high-precipitation intervals across all years.
The result is a fully reproducible pipeline from data fetch to labeled CSV export, ready to drive precipitation prediction models and downstream analytics.
Step inside an additive manufacturing workflow where high-frequency sensor data actually turns into decisions.
In this case study, we use dFL by Sophelio on a NIST Laser Powder Bed Fusion dataset to fuse machine commands, real melt-pool signals, and XCT scans into a single, engineer-ready workspace.
dFL’s custom visualizations surface process drifts layer-by-layer, then Python-based autolabelers transform those insights into an automated anomaly detector that flags power deviations across all 250 layers in minutes.
The result: a repeatable path from raw AM telemetry to targeted quality assurance and faster process optimization—without staring at every graph.
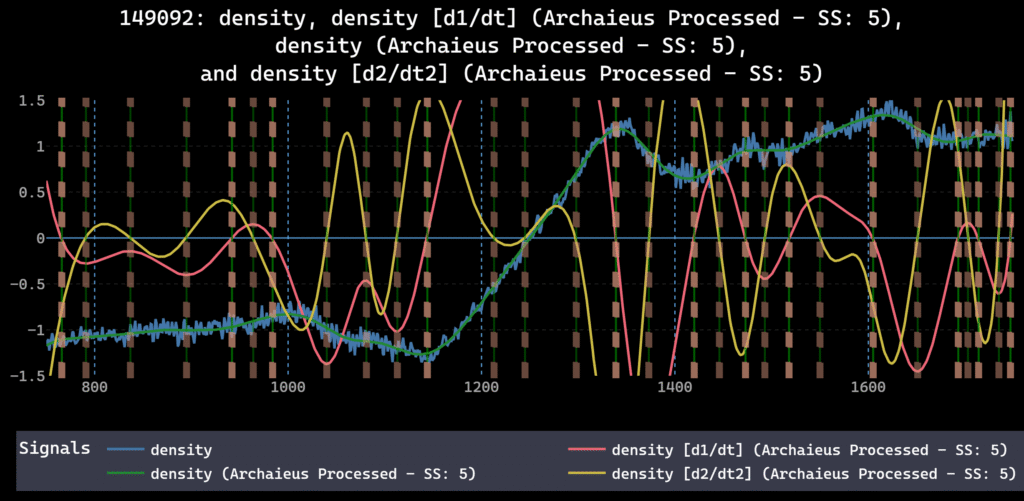
In this case study, we show how the Data Fusion Labeler (dFL) turns raw DIII-D tokamak signals into clean, reusable labels for ELMs and plasma regimes.
Starting from machine control parameters, magnetic probes, and filterscope diagnostics, dFL gives plasma physicists a single workspace to visualize shots, mark events manually, and then scale that knowledge with custom autolabelers.
An in-house ELM detector and an ONNX-based plasma mode model are plugged directly into dFL, enabling bulk autolabeling of ELM bursts and regimes across many shots in one pass.
The result is a fully traceable, ML-ready fusion dataset that supports better QA, faster analysis cycles, and more reliable ELM mitigation and prediction workflows.
Analyzing ECG from wearables in isolation is risky. Motion artifacts can masquerade as arrhythmias and derail your models.
In this demo, dFL ingests multimodal data from the ScientISST MOVE dataset and overlays ECG with synchronized accelerometer signals so you can instantly see which anomalies are true cardiac events and which are caused by movement.
We start with manual “Motion Artifact” labels as ground truth, then introduce a custom autolabeler that scans the full dataset and generates hundreds of artifact labels in seconds.
With every transformation tracked in dFL’s provenance, data teams walk away with a transparent, reproducible pipeline for building motion-aware wearable algorithms.
Enter Sophelio, where deep data expertise meets modern AI. We specialize in transforming complex, messy, and multimodal datasets into clean, actionable, and scalable intelligence. From scientifically interpretable models to end-to-end MLOps pipelines, our platform and tools are built for teams who know that great AI starts with knowing your data.
Compatible with Hugging Face, ROS/ROS2, PyTorch, MLflow, and LeRobot pipelines — so your team stays focused on building, not on config. Incorporate any Python library into your workflow.

MATLAB Signal Labeler vs. dFL: DSP depth, cost per seat, multi-user support, Python integration, and provenance. Side-by-side for sensor ML teams.
Read MoreManual labeling of 500 sensor recordings takes weeks. An ONNX classifier trained on 20 manually labeled examples can process the remaining 480 in minutes — with human review only on...
Read MoreA single DIII-D tokamak shot generates 60+ diagnostic channels at 1 kHz or higher. Before any ML model can train on that data, a physicist has to decide where every...
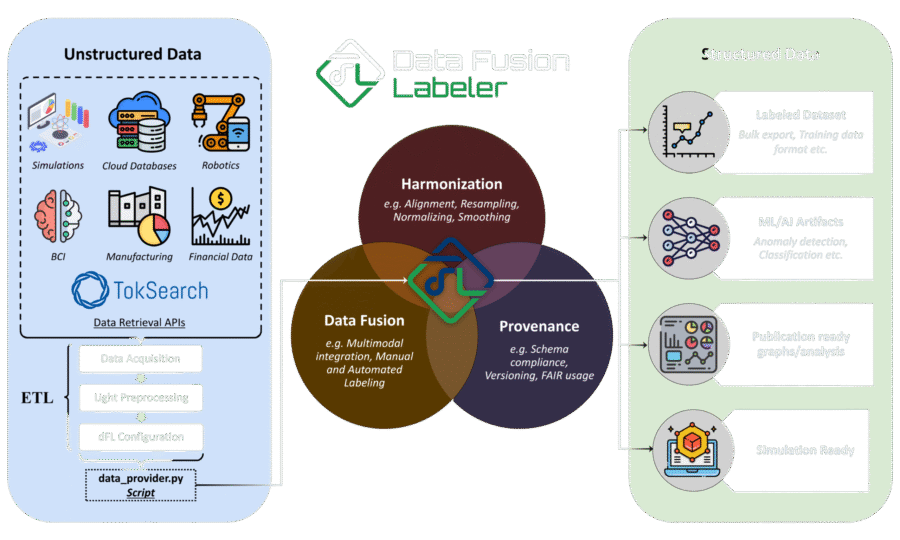
Read MoreThe Data Fusion Labeler (dFL) is a unified software framework that integrates data harmonization, data fusion, and provenance-rich labeling for fusion energy research. It transforms heterogeneous, asynchronous, and multimodal datasets—spanning diagnostics, simulations, and control telemetry—into schema-compliant, uncertainty-aware, and reproducible formats. This enables reliable scientific analysis, machine learning, and control workflows
Unlike traditional pipelines that treat transformations as independent or commutative steps, dFL enforces operator-ordering awareness—recognizing that the sequence of resampling, smoothing, or normalization operations fundamentally affects data integrity. Each operator is applied with reproducible context, ensuring transformations preserve phase relationships, units, and provenance. The result is higher-fidelity datasets and more reliable downstream analytics, even with modest models.
Every action in dFL—manual or automated—is recorded in a transparent provenance graph that captures the who, what, when, and why of every transformation. This produces an immutable data lineage, allowing users to regenerate, audit, or merge workflows across teams and institutions. dFL thereby supports FAIR (Findable, Accessible, Interoperable, Reproducible) data principles out of the box, dramatically reducing time lost to uncertainty or rework.
Yes. dFL incorporates a flexible auto-labeling engine capable of applying rules, thresholds, or learned models to detect and annotate relevant events or regimes within continuous data streams. It also supports hybrid, human-in-the-loop labeling, enabling experts to refine or override automated results. This combination accelerates curation of large datasets while maintaining interpretability and scientific control.
dFL is designed for cross-domain adaptability. It runs locally on workstations or scales to cloud and HPC environments, and can interface with SQL, HDF5, Parquet, or REST-based data stores. Because every harmonization and labeling operator is modular, organizations can adapt dFL to applications ranging from industrial monitoring and IoT sensor fusion to financial time-series analytics and AI model training pipelines—anywhere reproducible, multimodal data preparation is required.
Yes. dFL provides open APIs and plugin interfaces for seamless integration with existing data infrastructure—whether relational databases, object stores, or cloud orchestration tools. It supports Pythonic data access, command-line automation, and RESTful endpoints, allowing it to embed directly within modern ETL, MLOps, and DevOps pipelines.
Any domain struggling with heterogeneous, asynchronous, or multiformat data can benefit from dFL. Typical applications include:
Manufacturing and process monitoring (synchronizing sensor and control data)
Finance and econometrics (fusing multi-source time-series)
Healthcare and life sciences (harmonizing multimodal patient or assay data)
Energy and infrastructure (monitoring, forecasting, and anomaly detection)
In essence, dFL provides a universal framework for clean, harmonized, and trustworthy data streams across domains.
dFL maintains full audit trails and versioned exports, ensuring compliance with enterprise and regulatory standards such as ISO 8000, FAIR, and GDPR-style reproducibility and traceability. Each derived dataset can be traced back to its raw source and transformation lineage, empowering organizations to demonstrate data integrity, explainability, and provenance compliance during audits or model validations.
Organizations using dFL typically experience major reductions in data-preparation overhead—often by an order of magnitude—while achieving higher analytical reproducibility and transparency. More importantly, dFL’s harmonization framework enables teams to discover latent correlations and cross-modal patterns that were previously obscured by inconsistent preprocessing or missing context.
dFL is designed for uncertainty-aware data handling from the ground up. Users can embed custom uncertainty models directly into the ingestion layer using the data_provider and fetch_data methods, allowing each signal or feature to carry its own confidence intervals, variance estimates, or measurement noise models. These uncertainties are then propagated automatically through the harmonization pipeline—from trimming and resampling to smoothing and normalization—ensuring that downstream analyses and models retain a physically and statistically coherent error structure. This design enables traceable, physics-informed uncertainty management that reflects the realities of each data source rather than imposing a one-size-fits-all assumption.
Get hands-on with our full-stack ML tooling—label, harmonize, analyze, and export data with scientific precision. No setup, no guesswork, just powerful infrastructure built for data-driven teams. Try for free.