To a learning algorithm, these aren’t small differences. They describe different systems.
Common Preprocessing Order Mistakes
These errors appear constantly in production pipelines:
- Normalizing before train/test split. min/max or z-score statistics computed on the full dataset leak test set information….
- Imputing missing values before splitting. Forward fill, interpolation, or mean imputation before train/test split using global statistics causes the same problem.
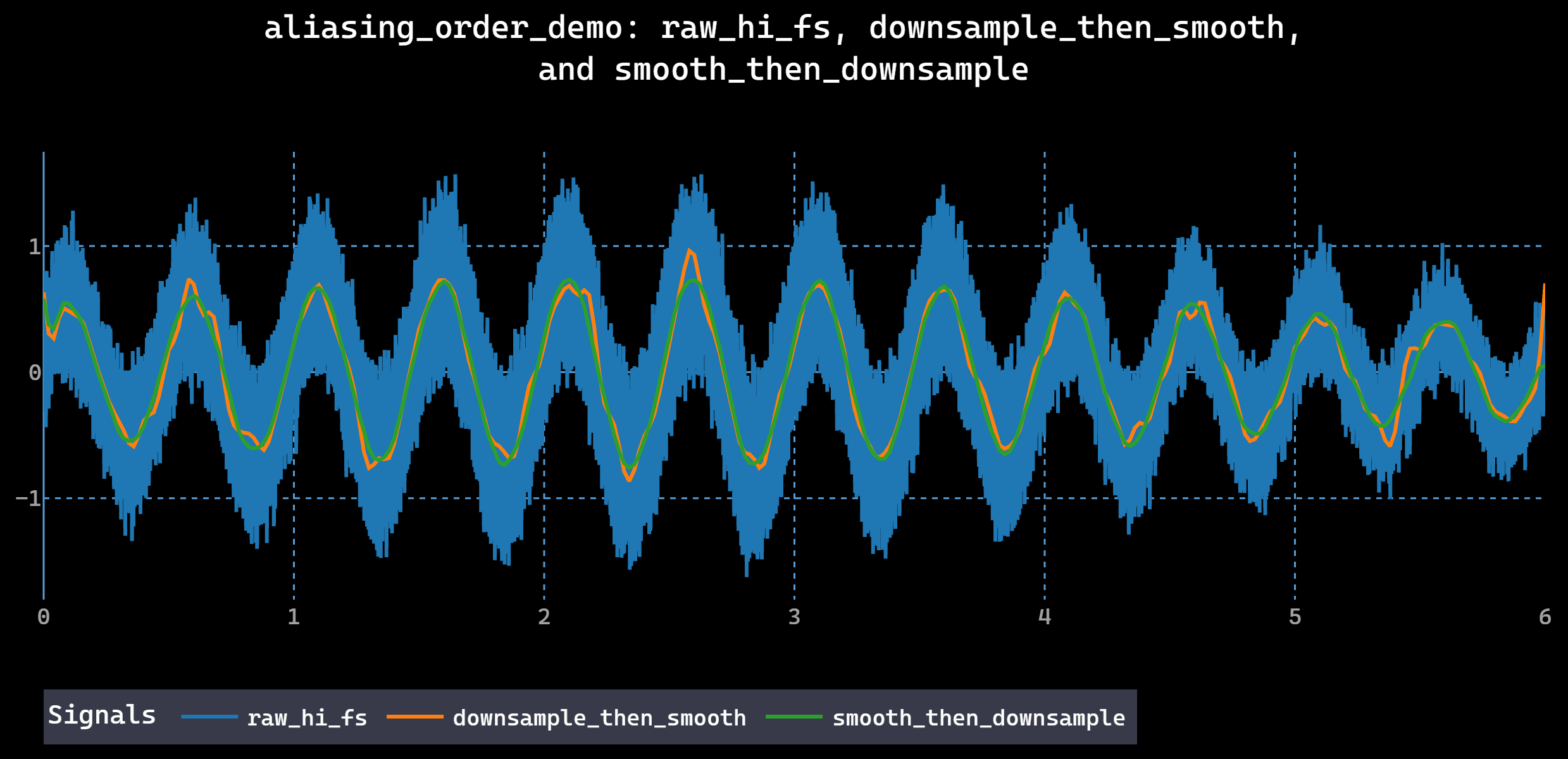
- Smoothing after downsampling. Aliasing introduces artificial patterns that the model treats as real signal.
- Using non-causal rolling windows. Rolling averages or lag features that include future data points create shortcuts that don’t exist at inference time.
- Normalizing before imputation. Scaling sparse data before filling gaps distorts the imputed values.
All of these inflate validation metrics while wrecking real world performance. For a visual walkthrough, see how common preprocessing steps introduce leakage without obvious warning signs.
How Preprocessing Introduces Data Leakage
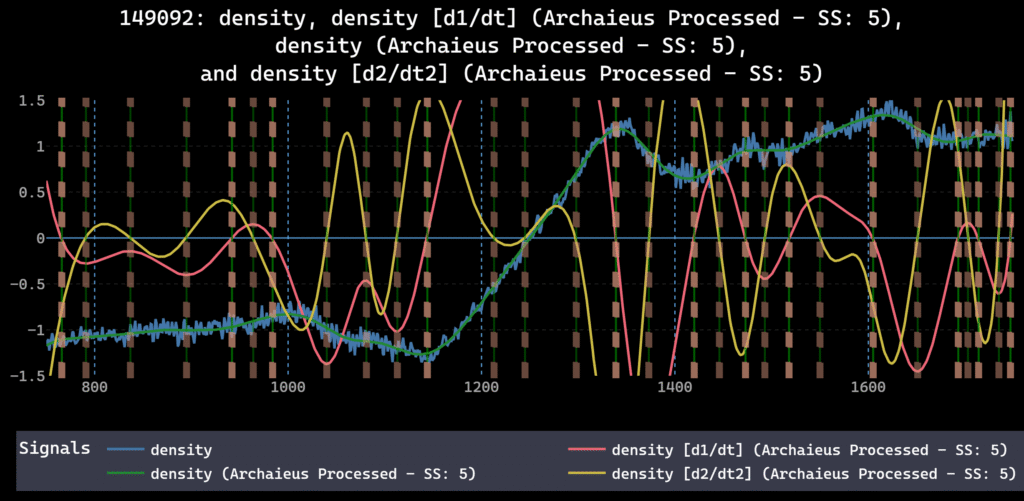
Data leakage happens when information that wouldn’t be available at prediction time influences training. In time series preprocessing, this comes from operations that use statistics computed on the full dataset or that blend past and future observations.
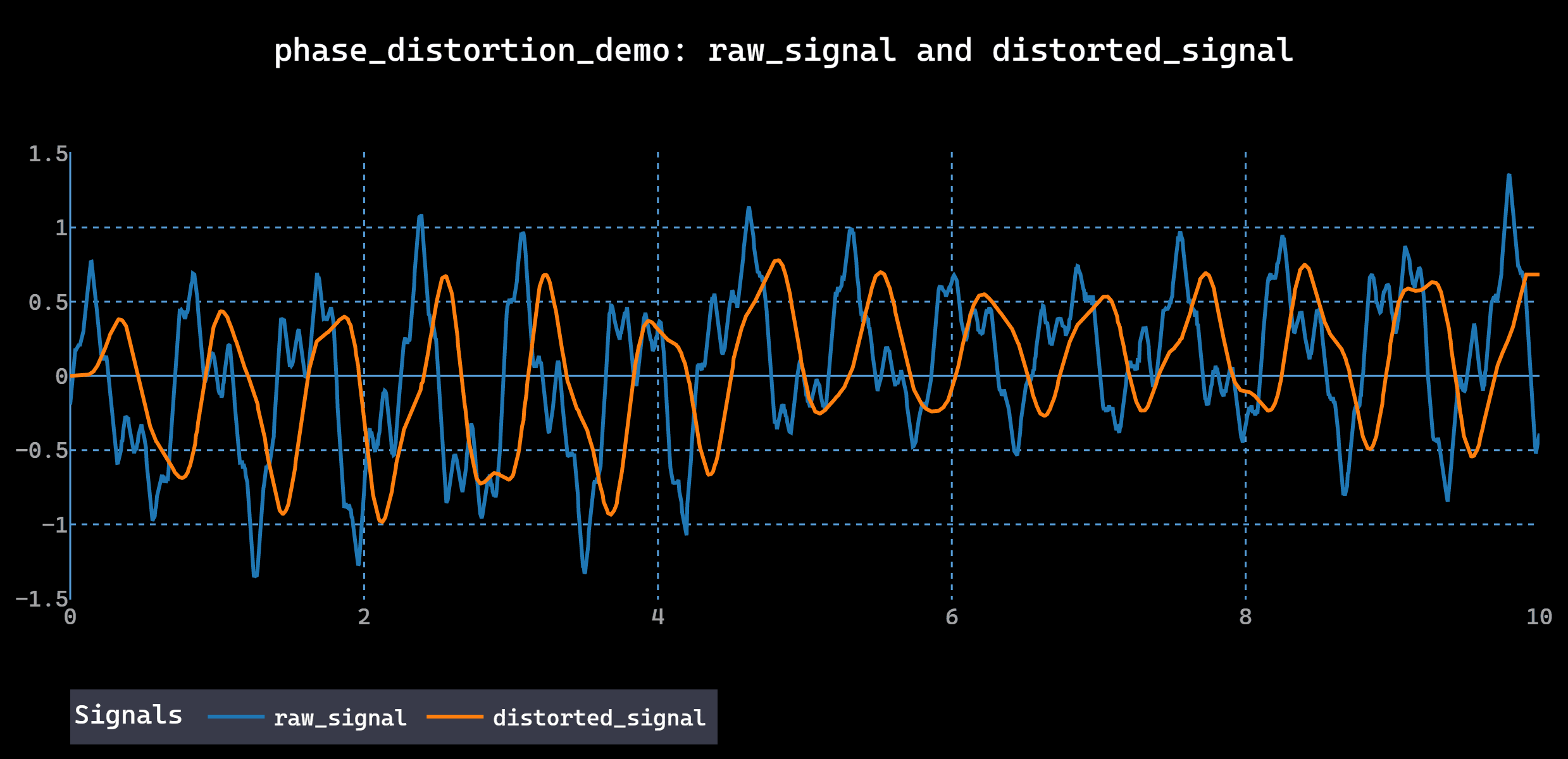
Consider a model trained to predict events from temporal patterns. If preprocessing shifts phase relationships, applies global normalization, or uses bidirectional interpolation, the model learns shortcuts that don’t exist in the real system.
Offline performance stays high. Validation metrics may improve. The model looks successful.

The failure hits in production. Predictions degrade under slightly different conditions. Deployment reveals instability. The model won’t generalize across datasets that should be comparable.
Teams blame the model or the data. Rarely the pipeline. A 2025 Artificial Intelligence Review documents how preprocessing leakage is one of the most common and overlooked causes of ML pipeline failure, noting that a high-profile study predicting suicidal ideation showed no predictive power once feature selection leakage was corrected.
Signs Your Preprocessing Pipeline Is Fragile
Pipelines built without attention to operator order break easily.
They work on the data they were developed on but respond poorly to small changes:
- A shift in sampling frequency requires retuning
- A missing sensor channel breaks assumptions
- Noise levels that differ modestly from training cause large swings in output
- Results can’t be reproduced on the same raw data months later
This happens because of implicit preprocessing assumptions about continuity, causality, scale, and temporal alignment that were never made explicit or tested.
Because these assumptions live upstream of the model, they’re hard to diagnose. When things break, the failure appears downstream, far from the cause.
Why Models Don’t Catch Preprocessing Errors
Models don’t reject bad inputs.
ML algorithms don’t know which correlations are meaningful and which were introduced by the pipeline. They don’t understand causality unless it’s enforced structurally. They’ll exploit any regularity that improves the objective, regardless of origin.
Pipelines that introduce feature leakage, aliasing, or artificial structure often produce models that look impressive during evaluation. The warning signs are subtle:
- Sensitivity to small perturbations
- Inconsistent behavior across datasets
- Difficulty reproducing results
- Real-time pipelines not validating
By the time these issues surface, the preprocessing steps that caused them may no longer be documented.
Reproducibility Failures in Time Series Preprocessing
Reproducibility failures in ML are often blamed on training randomness or data splits. For time series workflows, preprocessing pipeline order is frequently the deeper problem.
Reproducing a dataset means more than rerunning code. It means knowing exactly which operations ran, in what order, with what parameters, under what assumptions about causality and signal alignment.
When preprocessing order is implicit, results become fragile across time, teams, and environments. Two pipelines that look equivalent on paper can produce measurably different datasets. Models trained on them will diverge.
This is why teams sometimes can’t reproduce their own results months later, even with the same raw data.
Preprocessing Is Part of the Model
Every preprocessing pipeline defines an input representation. It encodes beliefs about which aspects of the signal matter, what can be discarded, and how different sources relate to each other.
Operator order isn’t a technical nuisance. It’s a design decision with consequences for correctness, stability, and trust.
This also explains why preprocessing choices are hard to fix later. Once a model is trained, you can’t easily separate what it learned from the system and what it learned from the pipeline.
Why Time Series Data Is Especially Sensitive
These issues exist across data types. Time series makes them worse.
Temporal ordering carries meaning. Causality constraints matter. Errors accumulate instead of averaging out. Labels and events depend on precise alignment across signals.
A small distortion introduced early in preprocessing can propagate forward, shaping features, labels, and predictions in ways that are hard to trace. A recent study in Scientific Reports documents how decomposition-based preprocessing methods can introduce information leakage that corrupts time series predictions.
This is why time series pipelines that “mostly work” still fail in subtle but consequential ways.
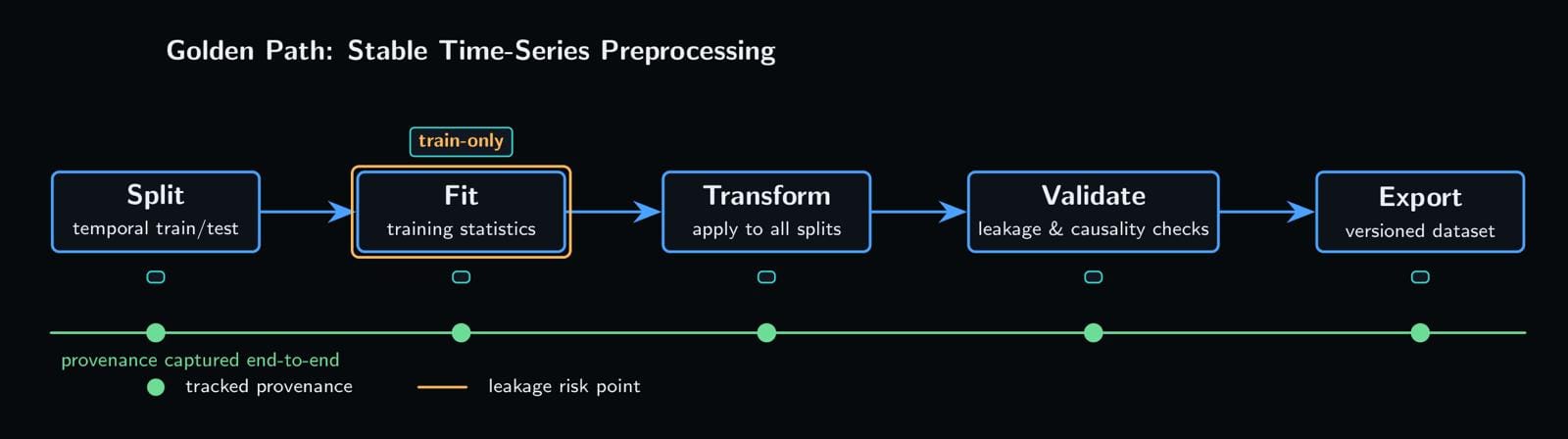
Building Stable Time Series Preprocessing Pipelines
To build preprocessing pipelines that hold up in production:
- Split before transforming. Apply temporal train/test splits before any operation that computes statistics (normalization, scaling, imputation). Fit on training data only, then apply to test. For a step-by-step walkthrough, see How to Avoid Data Leakage When….
- Smooth before downsampling. Anti-alias filtering prevents high frequency noise from folding into lower frequencies during resampling.
- Use causal windows only. Rolling features, lag features, and interpolation should look backward, not forward. No future data should influence past observations.
- Document operator order explicitly. Record the exact sequence of preprocessing steps in code and configuration. Version your pipelines.
- Test on out of distribution data. Before deployment, validate against data with different noise levels, sampling rates, or missing patterns than your training set.
- Treat preprocessing as a hyperparameter. The order of operations affects model performance. Test alternatives systematically. Scikit-learn’s Pipeline can help structure this correctly.